The development of speech recognition technology is a fascinating saga of human ingenuity aimed at replicating one of our most natural abilities—spoken language. Historically, humans learn languages with apparent ease, a skill that machines have only begun to approximate recently. Today, leading corporations such as IBM and Google have propelled their speech algorithms to impressive heights, boasting accuracy rates around 96%. Taking a closer look over time reveals recurring motifs and progressive mastery.
The Dawn of Speech Recognition
The journey began in the 1950s with the Audrey system, developed by Bell Laboratories, which recognized spoken digits. To recognize the numbers 1 to 9, spoken by a single voice and discerned with an accuracy of 90%, seemed nearly magical at the time.
This pioneering effort was followed in 1962 by IBM’s Shoebox, which expanded the scope by recognizing digits and simple commands, laying the foundational groundwork for future advancements.
Technological Strides in the 1970s and Beyond
In the 1970s, the Harpy system by Carnegie Mellon could understand sentences comparable to a three-year-old’s vocabulary. This era also saw the introduction of Hidden Markov Models (HMM), which significantly improved the efficacy of speech recognition systems. Still, the reduced error rates (WER) were relatively high compared to today’s end-to-end models like neural networks, which learn the entire process from raw data input.
The mid-1980s and 1996 witnessed significant consumer advancements with IBM’s Tangora, which could handle a 20,000-word vocabulary, and Dragon Systems released “Dragon Dictate,” the first consumer speech recognition product. Dragon Dictate was groundbreaking, allowing users to dictate text hands-free, which was a major leap toward practical everyday use.
The Modern Era: Deep Learning and Digital Assistants
By the early 2000s, speech recognition accuracy had reached about 80%, with substantial advancements following as AI and deep learning were increasingly integrated into speech-to-text technologies.
The era of digital voice assistants truly began shaping the market with the introduction of Siri in 2011, followed by competitors like Google Voice and Alexa. These technologies became fixtures in daily life, offering users unprecedented convenience by responding to voiced commands. Due to the rapid scaling effects of advanced deep learning methods, Microsoft announced in 2016 that it had reached human parity in speech recognition accuracy, based on WER.
Today’s speech recognition technologies are a far cry from their rudimentary predecessors. The transition from Hidden Markov Models to sophisticated Deep Neural Networks has drastically reduced error rates and improved the fluidity of interactions. Modern systems not only recognize speech but can adapt to individual voice patterns or provide generalized recognition across diverse voices. This capability is enhanced by combining natural language processing (NLP) with automatic speech recognition (ASR), allowing for a seamless conversion of spoken language into written text.
An Outlook: The Relevance of Empathic AI
Looking ahead, the potential for growth remains vast. Innovations like OpenAI’s Whisper hint at future advancements where speech recognition could further blur the lines between human and machine communication, trained on an unprecedented 680,000 hours of audio data. In stark contrast, earlier technologies based on HMM were limited to just a few hundred hours.
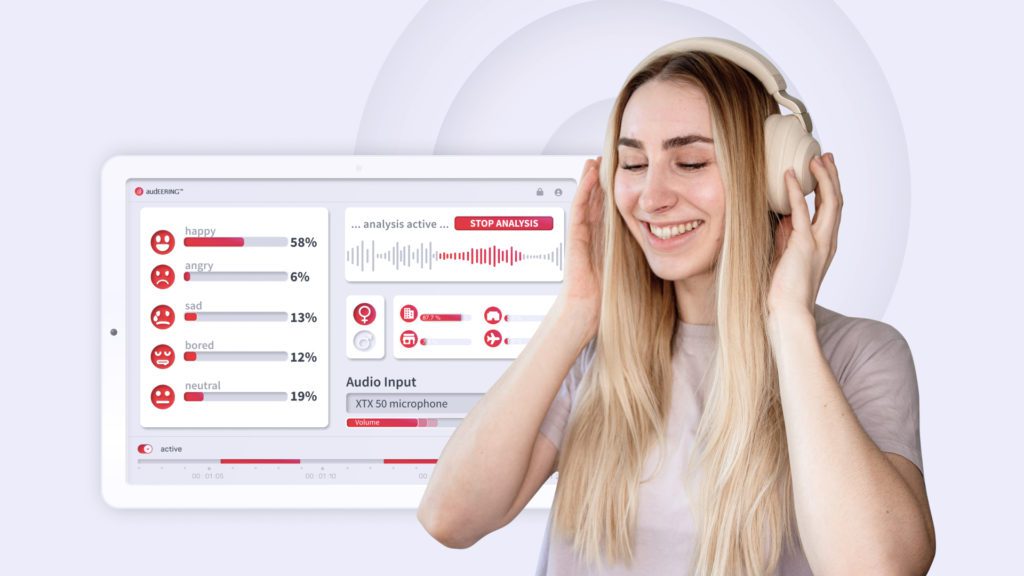
At audEERING®, we push the boundaries of conventional speech recognition by focusing on nuanced expression analysis that transcends simple text interpretation. Our holistic approach to speech analysis aims to enhance user well-being through empathetic AI, fostering a deeper connection in human-machine interaction. By prioritizing empathic competences in our technologies, we hope to contribute positively to the well-being of users, making everyday interactions more meaningful and supportive. The use cases are widespread, ranging from smartphones and smart speakers to call centers, healthcare, and automotive sectors.
This continuous evolution from the first experiments of the 1950s to today’s advanced technologies illustrates a trajectory of exponential improvement and adaptation. As we enhance our understanding and capabilities, the future of speech recognition looks promising, poised to offer even more sophisticated, intuitive, and user-centric communication solutions.
Contact us!
If you would like to find out more about the possibility of integrating voice into your case, get in touch with us and let voice touch you!